📋 About
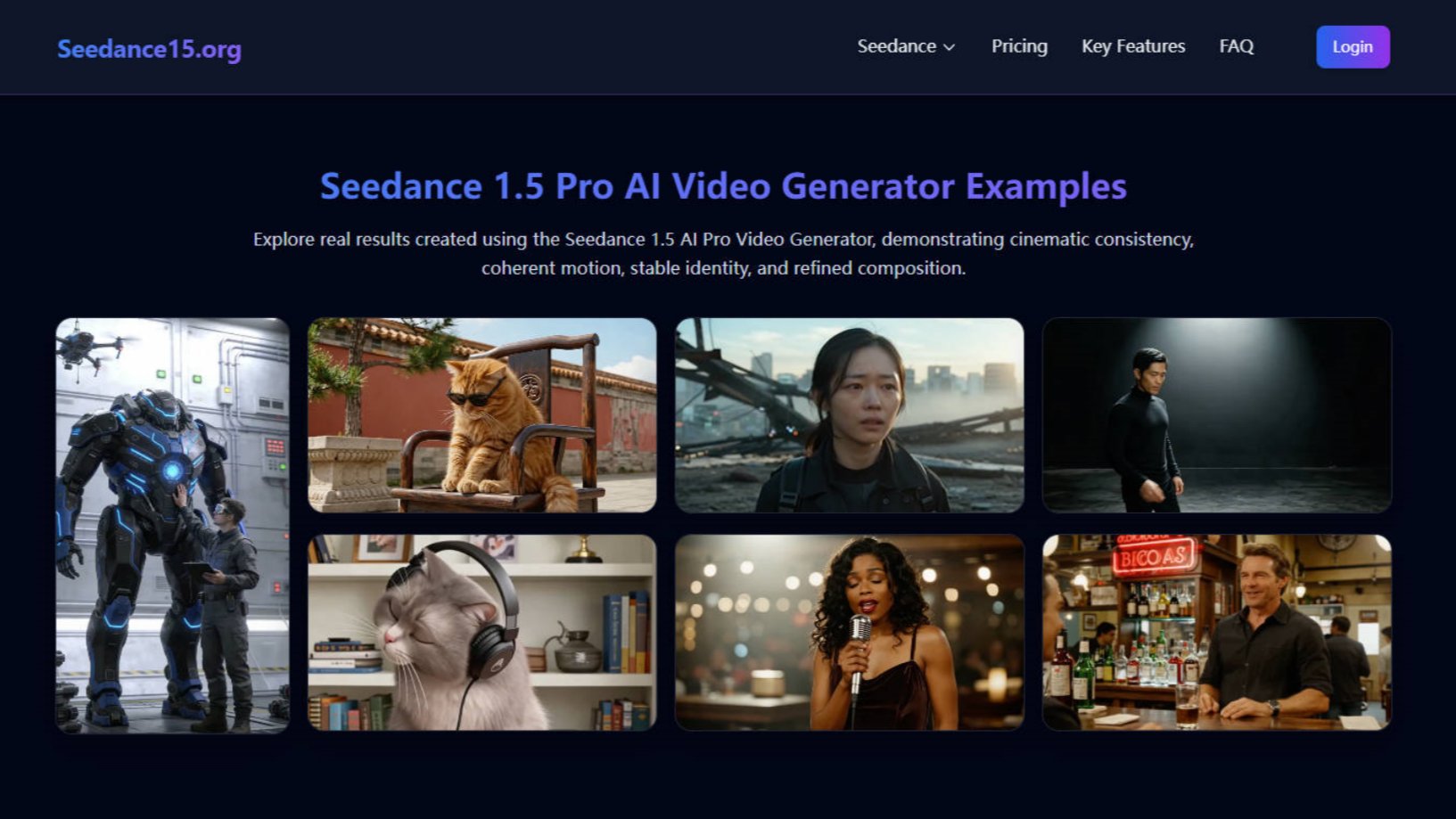
Seedance 1.5 is a film-grade AI video generation model by ByteDance, built for intelligent native audio-visual creation. It delivers precise audio-visual synchronization, fast inference, cinematic multi-shot storytelling, and strong emotional expression. With advanced semantic understanding, Seedance 1.5 accurately interprets complex prompts and turns ideas into coherent, expressive videos. Ideal for film production, short dramas, advertising, social media, and creative storytelling workflows.

Created by
hongzhenghe
📊 Product Details
- Status approved
- Launch Date Dec 27, 2025
- Upvotes 9
- Featured No
🏆 Badges & Awards
📈 Social Proof
Dec 27, 2025
×
![Gallery Image]()
Login to post a comment
Human-feedback training (SFT + RLHF) further refines timing, lip-sync, and emotional consistency.
Hope this helps.
Feel free to try it out and let us know how it performs for you. Your feedback is always welcome and really helps us improve.
It’s very good at handling the technical side: syncing audio and visuals, expressing emotions, styles, and motion without things falling apart.
Whether it feels “generic” mostly depends on the input. Vague prompts lead to generic results, but specific direction usually produces much more nuanced output.
The creativity still comes from you, the model just executes and explores variations really well.
Try pushing it with more specific ideas, and feel free to share feedback as you explore.
It uses a dual-branch Diffusion Transformer where audio and video are generated in parallel and aligned through cross-modal modules on a shared timeline.
Shared temporal modeling ensures speech, lip movement, music, and visual actions stay synchronized.
Human-feedback training (SFT + RLHF) further refines timing, lip-sync, and emotional consistency.
Hope this helps and feel free to try it out and share your feedback.
Login to write a review
No reviews yet. Be the first to review this product!